

搞 AI 大模型,实在太烧钱了。
我们知道,如今的生成式 AI 有很大一部分是资本游戏,科技巨头利用自身强大的算力和数据占据领先位置,并正在使用先进 GPU 的并行算力将其推广落地。这么做的代价是什么?
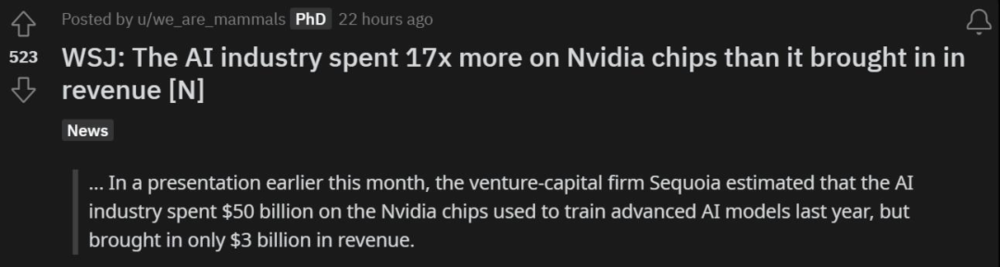
最近《华尔街日报》一篇有关明星创业公司的报道里给出了答案:投入是产出的 17 倍。
上个周末,机器学习社区围绕这个数字热烈地讨论了起来。
一、明星创业公司:几周估值翻倍,但没有收入
由知名投资人 Peter Thiel 支持的 AI 初创公司 Cognition Labs 正在寻求 20 亿美元估值,新一轮融资在几周之内就将该公司的估值提高了近六倍。
在如今火热的生成式 AI 领域里,Cognition 是一家冉冉升起的新星。如果你对它还不太熟悉,这里有它的两个关键词:国际奥赛金牌团队,全球首位 AI 程序员。
Cognition 由 Scott Wu 联合创立,其团队组成吸引眼球,目前只有 10 个人,但包含许多国际信息学奥林匹克竞赛的金牌选手。
该公司在今年 3 月推出了 AI 代码工具 Devin,号称“第一位接近人类的 AI 程序员”,能够自主完成复杂的编码任务,例如创建自定义的网站。从开发到部署,再到 debug,只需要人类用自然语言给需求,AI 就能办到。
该新闻很快就登上了众多媒体的头条,也成为了热搜:
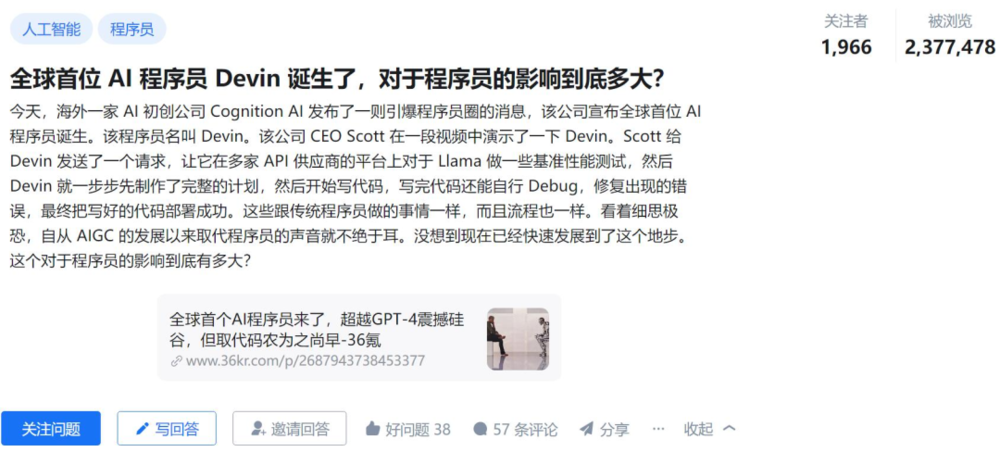
一些投资者表示,Devin 代表了人工智能的重大飞跃,并可能预示着软件开发的大规模自动化之路已经开启。
Cognition 虽然神奇,但它并不是个独苗。最近一段时间,生成式 AI 展现了超乎想象的吸金能力。去年 12 月,总部在法国的 Mistral 获得了 4.15 亿美元融资,估值达到 20 亿美元,比前一年夏天的一轮融资增长了大约七倍。
3 月初,旨在挑战谷歌网络搜索主导地位的 AI 初创公司 Perplexity 也传来新一轮融资的消息,新估值有望达到近 10 亿美元。
而在这其中,作为一家旨在提供 AI 自动代码工具的创业公司,Cognition 去年才开始研发产品,目前并没有获得有意义的收入数字。今年初,在 Founders Fund 牵头的一轮 2100 万美元融资中,该公司的估值达到了 3.5 亿美元。据介绍,美国著名创业投资家、创办 Founders Fund 的 Peter Thiel 帮助领导了对 Cognition 的投资。
AI 编写代码看起来是一个有前途的大模型应用方向,其他提供类似产品的公司也看到了增长势头。上个季度,微软的代码工具 GitHub Copilot 用户数量增长了 30% 达到 130 万。Magic AI 是 Cognition 的竞争对手,2 月份获得了 1.17 亿美元的投资。国内也有一些代码生成自动化工具的初创企业,在生成式 AI 技术爆发后正在加速行业落地。
尽管出现了令人鼓舞的增长迹象,新公司的估值也不断膨胀,但这种快速发展也引发了人们对于出现泡沫的担忧 —— 到目前为止,很少有初创公司能够展示他们如何赚钱,想要收回开发生成式 AI 的高昂成本,似乎还没有门道。
在 3 月的一次演讲中,红杉资本(Sequoia Capital)有投资人估计 AI 行业去年为了训练大模型,仅在英伟达芯片上就花费了 500 亿美元,而换来的收入是 30 亿美元。
所以说,不算电费,开销是收入的 17 倍。
怎么样,今年还玩得起吗?
二、出路在哪
如今生成式 AI 技术的爆发,可谓验证了强化学习先驱 Richard S. Sutton 在《苦涩的教训》中的断言,即利用算力才是王道。黄仁勋两周前在 GTC 上也曾表示:“通用计算已经失去动力,现在我们需要更大的模型、更大的 GPU,需要将 GPU 堆叠在一起…… 这不是为了降低成本,而是为了扩大规模。”
但是在千亿、万亿参数量的大模型出现之后,通过提升规模来提升智能的方法是否还可以持续,是一个无法回避的问题。更何况现在的大模型已经很贵了。
华尔街日报的文章迅速引起大量讨论。有网友认为:“资本支出通常就是一次性的,而投资的收入却是日积月累的。生成式 AI 刚刚起步,其后续的经济收益可能是巨大的。”

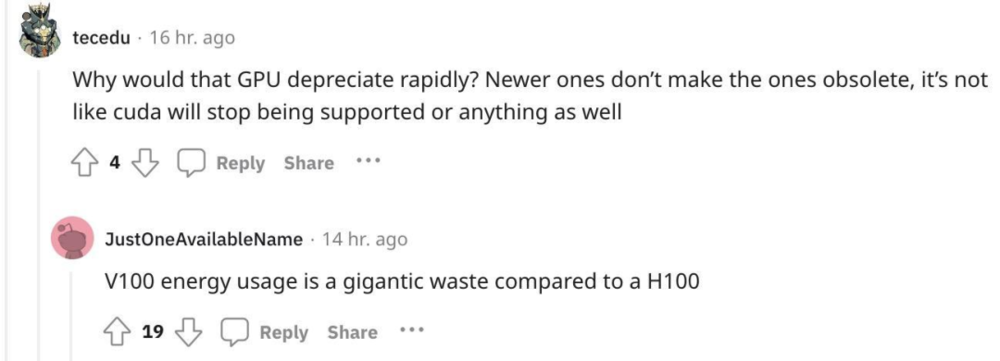
但这种乐观的观点很快遭到反驳,另一位网友指出:“资本的支出的确是一次性的,但 GPU 会相对较快地贬值。”

为什么说 GPU 会快速贬值呢?虽然较老版本的 GPU 也不会停止支持 CUDA(英伟达推出的运算平台)等等,但与 H100 相比,V100 的能源消耗是巨大的浪费。
毕竟同样也是在 3 月份,英伟达已经发布了全新一代 AI 加速的 GPU Blackwell 系列。
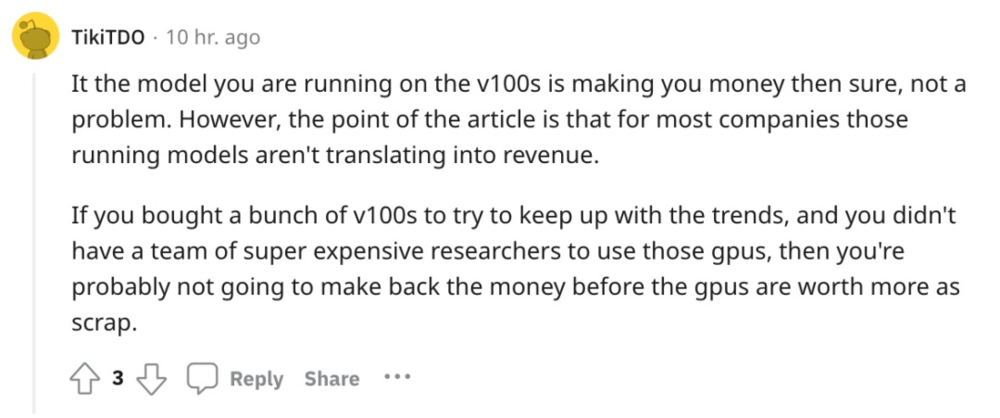
如果使用 V100 可以赚钱,那当然没问题。然而,如诸多媒体报道所述,对大多数公司来说,现阶段运行大模型并没有转化为实际收入。
另一方面,看看现在大模型每周都在推陈出新的状态,即使几年前的 GPU 在算力角度看可以接受,但大模型也在“快速折旧”。七年后的 AI,用现在的基础设施能支撑吗?
此外,如果一家公司花费大量成本来购买 V100,试图跟上生成式模型的趋势,那么可能就会出现研究团队雇佣成本不足的问题,那么最终可能还是无法做出有实际应用、经济收益的产品。
值得注意的是,许多 LLM 都需要额外的处理层来消除幻觉或解决其他问题。这些额外的层显著增加了生成式模型的计算成本。这不是 10% 的小幅增长,而是计算量增长了一个数量级。并且许多行业可能都需要这种改进。

图源:Reddit 用户 @LessonStudio
从行业的角度讲,运行生成式大模型需要大型数据中心。英伟达已经非常了解这个市场,并持续迭代更新 GPU。其他公司可能无法仅仅投资数百亿美元来与之竞争。而这些 GPU 需求还只是来自各大互联网公司的,还有很多初创公司,例如 Groq、Extropic、MatX、Rain 等等。
最后,也有人给出了这种夸张投入的“合理性”:坐拥大量现金的微软、谷歌和 Meta,他们因为反垄断法规而无法继续收购,因而只能选择将资金投入 AI 技术发展。而 GPU 支出的折旧,可以作为损失避免缴纳更多税款。
但这就不是创业公司所要考虑的事了。
无论如何,竞争会决出胜者。无论花掉多少钱,成为第一可能就会带来潜在的收益……
但是什么样的收益,我们还无法作出预测。难道,生成式 AI 真正的赢家是英伟达?
参考链接:
https://www.wsj.com/tech/ai/a-peter-thiel-backed-ai-startup-cognition-labs-seeks-2-billion-valuation-998fa39d
https://www.cognition-labs.com/introducing-devin
https://analyticsindiamag.com/meet-the-creator-of-devin-a-child-prodigy-who-is-making-coding-obsolete/
https://www.reddit.com/r/MachineLearning/comments/1bs1ebl/wsj_the_ai_industry_spent_17x_more_on_nvidia/
