
 几十年前,柯达说出了那句经典的广告语,「你负责按快门,剩下的交给我们」。在未来,AI 兴许也会打起类似的广告,「你什么都不用干,剩下的交给我们」。
几十年前,柯达说出了那句经典的广告语,「你负责按快门,剩下的交给我们」。在未来,AI 兴许也会打起类似的广告,「你什么都不用干,剩下的交给我们」。
人工智能领域缺钱,但这两个月来,他们不缺「好消息」。
Google 母公司 Alphabet 旗下的 DeepMind,先推出了蛋白质结构预测 AI——AlphaFold 2,为困扰了生化学界 50 年的难题提供了解决思路;接着又发论文介绍「进阶版 AlphaGo」——MuZero,这个 AI 能在完全不知道棋局规则和人类知识的情况下,自己摸索,决策,并赢棋。
2021 年的第一周还没过去,AI 就再次向人类发起了「挑衅」。
AI 研究机构 OpenAI,继去年部分开放了 AI 模型 GPT-3 并引爆整个科技圈之后,又于近期连发了 DALL·E 和 CLIP 这两个连接文本与图像的神经网络。它们刚一面世,就点燃了整个 AI 社区。因为人们发现有了这些神经网络,就能通过自然语言操纵视觉概念,比如,你输入「一把牛油果造型的扶手椅」,它们就能通过图像合成,「凭空捏造」出一系列的目标图像。

什么是人工智能的未来?《麻省理工科技评论》认为就是「那把牛油果造型的扶手椅」,因为 AI 又往「构建多模态 AI 系统」这个长期目标又迈近了一大步。
「干掉」程序员后,AI 又对艺术家下手了
DALL·E 率先在社交网络上刷起了屏,因为人们放出了很多看起来像凭空捏造的合成图,比如「立方体状的豪猪」、「由乌龟变成的长颈鹿」和「竖琴状的蜗牛」,这些就像是超现实主义画家萨尔瓦多·达利在梦里会看到的奇异造物。有意思的是,DALL·E 也正是「Dalí」和皮克斯动画形象「WALL-E」的合成词。

竖琴状的蜗牛
DALL·E 是 OpenAI 基于 GPT-3 开发的一种「用字生图」的 AI。GPT-3 本质上是一个自然语言处理(NLP)模型,机器就是依靠 NLP 理解了我们平时说的「人话」。在 1750 亿参数量基础上的 GPT-3,展现出了惊人的翻译、问答和文本填空能力,写出来的新闻甚至通过了图灵测试,人们分辨不出是人还是机器写的。
GPT-3 可扩展性非常强大,甚至可以用在无代码开发领域。无代码就是就是不用敲代码也可以直接生成程序,而 GPT-3 就是强大的无代码开发平台,只要对它输入你想要什么样的网页或者 app,它就能帮你直接生成。因此,业内认为基层码农将会被 AI「干掉」。
而 DALL·E 是 GPT-3 的一个小版本,使用了 120 亿个参数。它使用的是「文本-图像对」的数据集,而非像 GPT-3 那样广泛的数据集。「从原理上来看,它应该就是 GPT-3 在文本合成图像方向上的扩展版本。」Keras 创始人 François Chollet 表示。
DALL·E 可以利用自然语言从文字说明中「捏造」图像,就像 GPT-3 创建网站和写故事一样。DALL·E 生成复杂图像的表现,让人惊喜,比如下面这则包含多个要素的目标文本:「一只戴着红帽子、黄手套、蓝衬衫和绿裤子的刺猬」。
要正确地解释这句话,DALL·E 不仅要正确地将每件衣服与动物组合在一起,还要将(帽子、红色)、(手套、黄色)、(衬衫、蓝色)和(裤子,绿色)形成各种联想,而且还不能混淆它们。

这张图显示了 DALL·E 掌握了理解相对定位、堆叠对象和控制多个属性方面的能力|OpenAI
因为足够强大的 NLP 底层,DALL·E 还能执行多种图像到图像的翻译任务,比如「参照上面的猫在下面生成草图」、「画出和上面一样的茶壶,并在茶壶上写上『GPT』」等等。除此之外,DALL·E 也能理解地理事实,生成让人信服的「中国食物的图片」,它甚至也能理解「时间」,画出从 20 年代起发明的电话,甚至联想未来的手机。
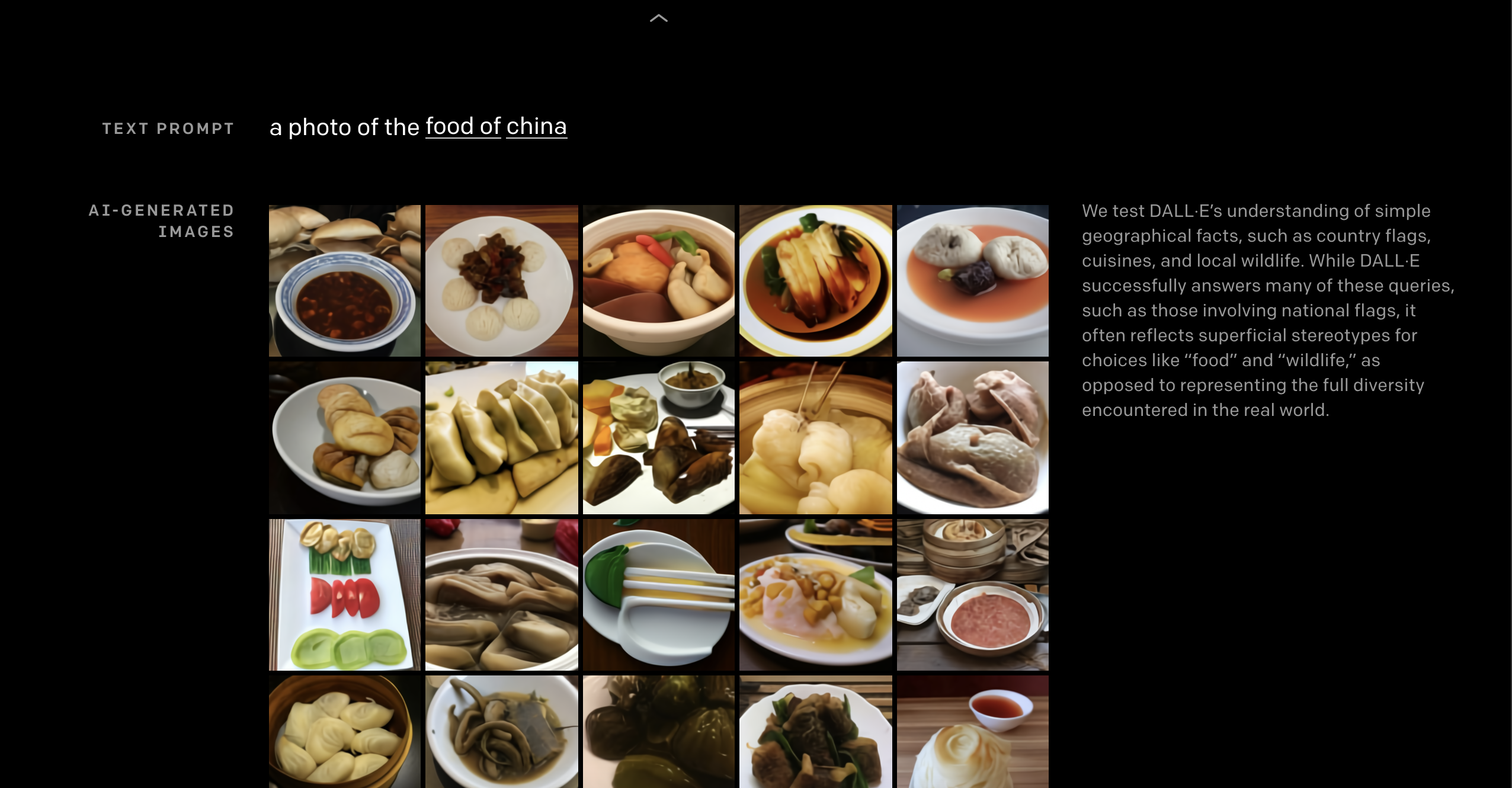
中国食物

各个年代的手机
另外,它还能根据文字指令「看日出的水豚鼠」,生成诸如波普风格、超现实主义风格、浮世绘风格等不同艺术风格的画作,还能渲染出各个角度下美洲狮的细节。
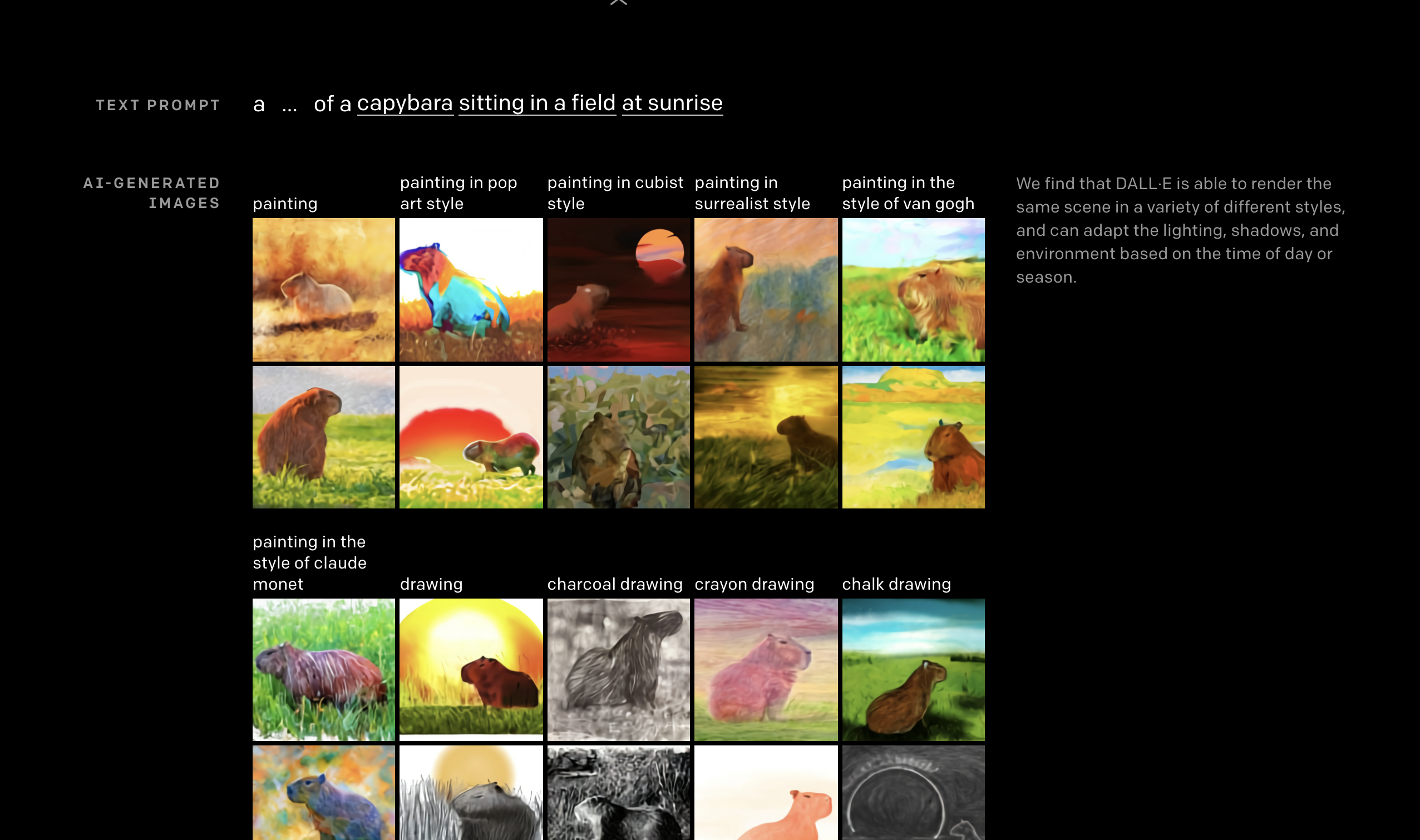
看日出的水豚鼠
Coursera 创始人、斯坦福大学教授吴恩达还特别对 OpenAI 表示祝贺,并挑选了自己最喜欢的「蓝色衬衫 + 黑色长裤」的 AI 生成图。DALL·E 能不能成为艺术家不敢说,但成为 AI 大神的着装参谋,绰绰有余。
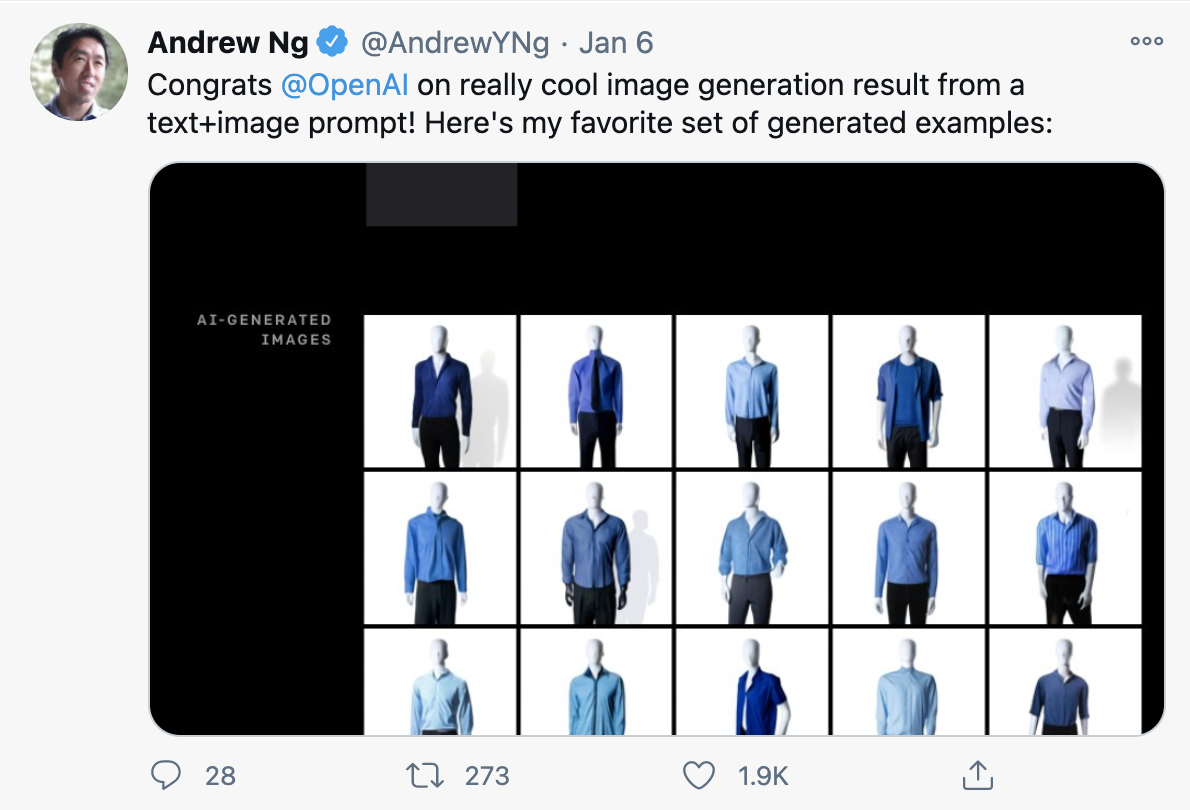
吴恩达的 Twitter
一个生成图像,一个匹配文字和图像
但 DALL·E 目前也存在局限,比如当人们引入更多的对象时,DALL-E 容易混淆对象及其颜色之间的关联。另外,用意思相同的词重新表述指令,生成的图像也不一致。还有一些迹象表明,DALL·E 只是在模仿它在网上看到的图片,而不是生成新颖的图像。
而 OpenAI 同期发布的 CLIP(Contrastive Language–Image Pre-training),则是为了加强文本和图像的关联程度而诞生的。CLIP 是一个从互联网上收集的 4 亿对图像和文本来进行训练的多模态模型。
CLIP 使用了大量可用的监督资源,即网络上找到的文本-图像对。这些数据用于创建 CLIP 的代理训练任务,即给定一张图像,然后预测数据集中 32768 个随机采样文本片段中哪个与该图像匹配。
简单来说,CLIP 能根据视觉类别名称,自己分类图像,创新点在于它学会了识别图像,而不是像大多数现有模型那样,通过数据集中的标签(比如「猫」或「香蕉」)识别图像,而是从互联网上获取的图像及其标题中识别图像。
CLIP 瞄向的,就是当前深度学习的两个「痛点」:一是数据集构建成本高昂;二是数据集应用范围狭窄。具体来说,深度学习需要大量的数据,而视觉模型传统上采用人工标注的数据集进行训练,这些数据集的构建成本很高,而 CLIP 可以从互联网上已经公开可用的文本图像对中自行学习;CLIP 可以适应执行各种各样的视觉分类任务,而不需要额外的训练样本。
另外,实验结果表明,经过 16 天的 GPU 训练,在训练 4 亿张图像之后,Transformer 语言模型在 ImageNet 数据集上仅实现了 16% 的准确率。CLIP 则高效得多,实现相同准确率的速度快了大约 9 倍。

简单来说,DALL·E 可以基于文本直接生成图像,CLIP 则能够完成图像与文本类别的匹配。
出门问问 CEO 李志飞曾告诉极客公园(ID: GeekPark),「GPT-3 随着数据和参数规模增大而展现出的学习能力曲线,目前也还没有要停止的意思。虽然 AI 的学习能力还没有达到大家公认的「摩尔定律」,但是过去几年确实看到模型每几个月就翻倍。可以预测到的是,GPT-4 参数又会增大至少 10 倍,而且处理的数据将会更加多模态(文字、图像、视觉、声音)。」
OpenAI 首席科学家 Ilya Sutskever 也在推特上发文表示:「人工智能的长期目标是构建多模态神经网络,即 AI 能够学习不同模态之间的概念(文本和视觉领域为主),从而更好地理解世界。而 DALL·E 和 CLIP 使我们更接近『多模态 AI 系统』这一目标。」
DALL·E 和 CLIP 的出现,让人们看到自然语言与视觉的壁垒正在被逐渐打通。
几十年前,柯达说出了那句经典的广告语,「你负责按快门,剩下的交给我们」。在未来,AI 兴许也会打起类似的广告,「你什么都不用干,剩下的交给我们」。
