

这是一只AI生出的小AI。
谷歌大脑的Quoc Le团队,用神经网络架构搜索 (NAS) ,发现了一个目标检测模型。长这样:
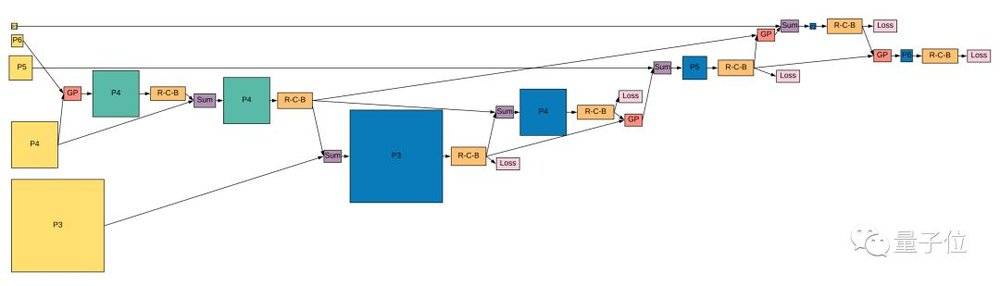
△ 看不清请把手机横过来
它的准确率和速度都超过了大前辈Mask-RCNN;也超过了另外两只行业精英:FPN和SSD。
模型叫做NAS-FPN。大佬Quoc Le说,它的长相完全在想象之外,十分前卫:

△ 喜讯发布一日,已收获600颗心
AI的脑洞果然和人类不一样。对比一下,目标检测界的传统方法FPN (特征金字塔网络) 长这样:
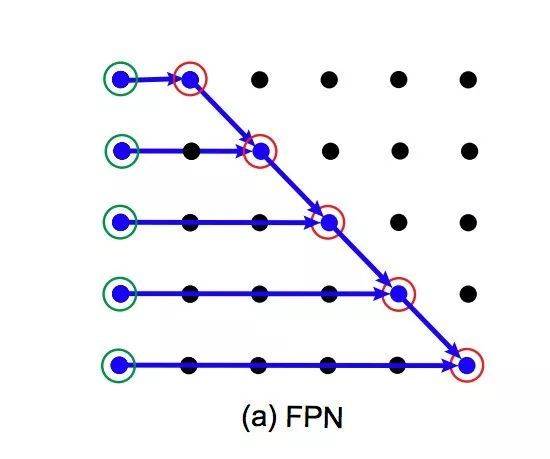
谷歌大脑说,虽然网络架构搜索 (NAS) 并不算新颖,但他们用的搜索空间与众不同。
怎么搜出来?
在NAS-FPN出现之前,地球上最强大的目标检测模型,架构都是人类手动设计的。

△ 这是Mask-RCNN的成果
NAS是一种自动调参的方法,调的不是训练超参数,是网络架构超参数:比如网络多少层、每层都是什么算子、卷积层里的过滤器大小等等。
它可以在许多许多不同的架构里,快速找到性能最好的那一个。

所以,要把目标检测的常用架构FPN (特征金字塔网络) 和NAS结合起来,发现那只最厉害的AI。
但问题是搜索空间太大,特征横跨许多不同的尺度。
于是,团队基于RetinaNet框架,设计了一个新的搜索空间:
这里,一个FPN是由许多的“合并单元 (Merging Cells) ”组成的。
是要把输入的不同尺度/分辨率的特征层,合并到RetinaNet的表征里去。
具体怎样合并?这是由一个RNN控制器来决定的,经过四个步骤:
一是,从输入里任选一个特征层;
二是,从输入里再选一个特征层;
三是,选择输出的特征分辨率;
四是,选择一种二进制运算,把两个特征层 (用上一步选定的分辨率) 合并起来。
第四步有两种运算可选,一种是加和 (sum) ,一种是全局池化 (Global Pooling) 。两个都是简单、高效的运算,不会附加任何带训练的参数。
一个Cell就这样合并出来了,但这只是中间结果。把它加到刚才的输入列表里,和其他特征层排在一起。
然后,就可以重新选两个特征层,重复上面的步骤一、二、四,保持分辨率不变。
(团队说,如果要避免选到相同分辨率的两个特征层,就不要用步长8。2和4是比较合适的步长。)
就这样,不停地生成新的Cell。
停止搜索的时候,最后生成的5个Cell,会组成“被选中的FPN”出道。

那么问题来了,搜索什么时候能停?
不是非要全部搜索完,随时都可以退出。反正分辨率是不变的,FPN是可以随意扩展的。
团队设定了Early Exit (提前退出) 机制,用来权衡速度和准确率。
最终发布NAS-FPN的,是AI跑了8,000步之后,选取最末5个Cell生成的网络。回顾一下:
从原始FPN (下图a) 开始,它走过的路大概是这样的:
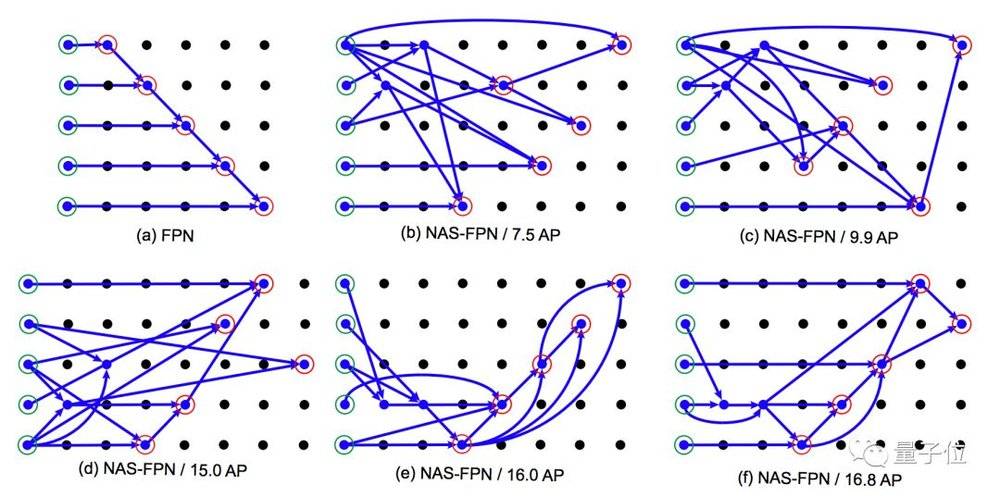
跑得越久,生成的网络就越蜿蜒。
模型怎么样?
NAS-FPN可以依托于各种骨架:MobileNet,ResNet,AmoebaNet……
团队选择的是AmoebaNet骨架。
那么,用COCO test-dev数据集,和那些强大的前辈比一比高清大图检测效果。
比赛结果发布:

NAS-FPN拿到了48.3的AP分,超过了Mask-RCNN,并且用时更短 (右边第二列是时间) 。
另外一场比赛,是移动检测 (320×320) ,NAS-FPN的轻量版本,跑在MobileNet2骨架上:

超过了厉害的前辈SSD轻量版,虽然,还是没有赶上YOLOv3。
△ YOLOv3过往成果展
不过,打败Mask-RCNN已经是值得庆祝的成就了。
One More Thing
NAS既然如此高能,应该已经搜索过很多东西了吧?
谷歌大脑的另一位成员David Ha列出了7种:
1) 基于CNN的图像分类器,2) RNN,3) 激活函数,4) SGD优化器,5) 数据扩增,6) Transformer,7) 目标检测。

并发射了直击灵魂的提问:下一个被搜的会是什么?
他的同事摘得了最佳答案:NAS啊。
△ NAS
